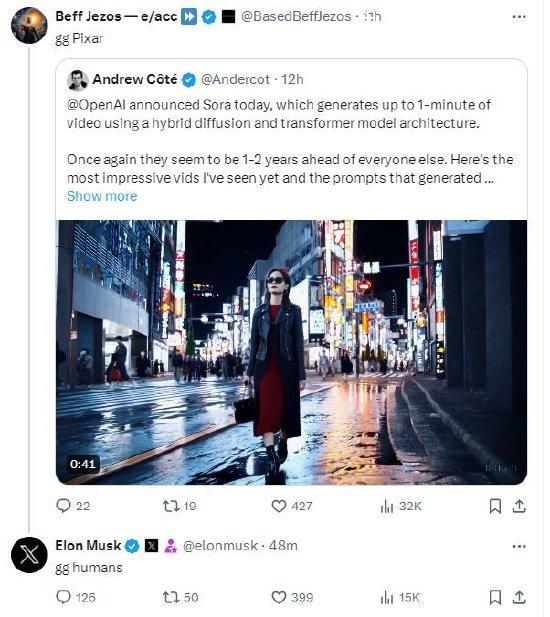
Sora到底懂不懂物理世界?一场头脑风暴正在AI圈大佬间展开
导读:Sora到底是不是物理引擎甚至世界模型?图灵奖得主YannLeCun、Keras之父FrancoisChollet等人正在深入探讨。最近几天,OpenAI发布的视频生成模...
Sora到底是不是物理引擎甚至世界模型?图灵奖得主YannLeCun、Keras之父FrancoisChollet等人正在深入探讨。

最近几天,OpenAI发布的视频生成模型Sora成了全世界关注的焦点。
和以往只能生成几秒钟视频的模型不同,Sora把生成视频的长度一下子拉长到60秒。而且,它不仅能了解用户在Prompt中提出的要求,还能get到人、物在物理世界中的存在方式。
以经典的「海盗船在咖啡杯中缠斗」为例。为了让生成效果看起来逼真,Sora需要克服以下几个物理难点:
规模和比例的适应:将海盗船缩小到能够在咖啡杯中缠斗的尺寸,同时保持它们的细节和结构,是一个挑战。AI需要理解和调整这些对象在现实生活中的相对尺寸,使得场景在视觉上显得合理;
流体动力学:咖啡杯中的液体会对海盗船的运动产生影响。AI模型需要模拟液体动力学的效果,包括波浪、溅水和船只移动时液体的流动,这在计算上是复杂的;
光线和阴影的处理:为了使场景看起来真实,AI需要精确地模拟光线如何照射在这个小型场景中,包括咖啡的反光、船只的阴影,以及可能的透光效果;
动画和运动的真实性:海盗船的运动需要符合真实世界的物理规律,即使它们被缩小到咖啡杯中。这意味着AI需要考虑到重力、浮力、碰撞以及船体结构在动态环境中的行为。
……
虽然生成效果还有些瑕疵,但我们能明显感觉到,Sora似乎是懂一些「物理」的。英伟达高级研究科学家JimFan甚至断言,「Sora是一个数据驱动的物理引擎」,「是一个可学习的模拟器,或『世界模型』」。
部分研究者同意这样的观点,但也有不少人反对。
YannLeCun:生成视频的过程与基于世界模型的因果预测完全不同
图灵奖得主YannLeCun率先亮明观点。在他看来,仅仅根据prompt生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测完全不同。
他接着讲到,模型生成逼真视频的空间非常大,视频生成系统只需要产生一个合理的示例就算成功。不过对于一个真实视频而言,其合理的后续延续空间却非常小,生成这些延续的代表性片段,特别是在特定行动条件下,任务难度更大。此外生成视频的后续内容不仅成本高昂,实际上也毫无意义。
因此,YannLeCun认为,更理想的做法是生成视频后续内容的抽象表达,并消除与我们可能所采取动作无关的场景中的细节。
当然,他借此又PR了一波JEPA(JointEmbeddingPredictiveArchitecture,联合嵌入预测架构),认为上述做法正是它的核心思想。JEPA不是生成式的,而是在表示空间中进行预测。与重建像素的生成式架构(如变分自编码器)、掩码自编码器、去噪自编码器相比,联合嵌入架构(如Meta前几天推出的AI视频模型V-JEPA)可以产生更优秀的视觉输入表达。
FrançoisChollet:只让AI看视频学不成世界模型
Keras之父FrançoisChollet则阐述了更细致的观点。他认为,像Sora这样的视频生成模型确实嵌入了「物理模型」,但问题是:这个物理模型是否准确?它能否泛化到新的情况,即那些不仅仅是训练数据插值的情形?
Chollet强调,这些问题至关重要,因为它们决定了生成图像的应用范围——是仅限于媒体生产,还是可以用作现实世界的可靠模拟。
Chollet通过海盗船在咖啡杯中缠斗的例子,讨论了模型能否准确反映水的行为等物理现象,或者仅仅是创造了一种幻想拼贴。这里,他指出模型目前更倾向于后者,即依赖于数据插值和潜空间拼贴来生成图像,而不是真实的物理模拟。有人将这种行为类比为人类做梦,认为Sora其实只是达到了人类做梦的水平,但是逻辑能力依然不行。
Sora生成的人类考古视频,椅子在画面中凭空出现,而且不受重力影响漂浮在空中。
Chollet指出,通过机器学习模型拟合大量数据点后形成的高维曲线(大曲线)在预测物理世界方面是存在局限的。在特定条件下,大数据驱动的模型能够有效捕捉和模拟现实世界的某些复杂动态,比如预测天气、模拟风洞实验等。但这种方法在理解和泛化到新情况时存在局限。模型的预测能力依赖于其训练数据的范围和质量,对于那些超出训练数据分布的新情况,模型可能无法准确预测。
所以,Chollet认为,不能简单地通过拟合大量数据(如游戏引擎渲染的图像或视频)来期望得到一个能够泛化到现实世界所有可能情况的模型。这是因为现实世界的复杂性和多样性远超过任何模型能够通过有限数据学习到的。
田渊栋:学习物理需要主动学习或者策略强化学习
针对JimFan的观点,一些研究者提出了更激进的反驳,认为Sora并不是学到了物理,只是看起来像是学到了罢了,就像几年前的烟雾模拟一样。也有人觉得,Sora不过是对2D像素的操纵。
当然,JimFan对「Sora没有在学习物理,而只是操纵2D像素」这一说法进行了一系列反驳。他认为,这种观点忽略了模型在处理复杂数据时所展现出的深层次能力。就像批评GPT-4不是学习编码,只是随机挑选字符串一样,这种批评没有认识到Transformer模型在处理整数序列(代表文本的tokenID)时所表现出的复杂理解和生成能力。
对此,谷歌研究科学家KevinPMurphy表示,他不确定最大化像素的可能性是否足以促使模型可靠地学到精确的物理,而不是看似合理的动态视觉纹理呢?是否需要MDL(Minimumdescriptionlength,最小描述长度)呢?
与此同时,知名AI学者、MetaAI研究科学家田渊栋也认为,关于Sora是否有潜力学到精确的物理(当然现在还没有),其背后的关键问题是:为什么像「预测下一个token」或「重建」这样简单的思路会产生如此丰富的表示?
他表示,损失函数如何被激发的并不重要,损失函数的设计动机(无论多么哲学化或复杂)并不直接决定模型能否学习到更好的表示。事实上,复杂的损失函数可能与看起来很简单的损失函数实际上产生了类似的效果。
最后他称,为了更好地理解事物,我们确实需要揭开Transformers的黑匣子,检查给定反向传播的训练动态,以及如何学习隐藏的特征结构,并探索如何进一步改进学习过程。
田渊栋还表示,如果想要学习精确的物理,他敢打赌需要主动学习或者策略强化学习(无论如何称呼它)来探索物理的精细结构(例如物体之间的相互作用、硬接触)。
其他观点:Sora被认为是「数据驱动的物理引擎」太荒谬
除了众多AI圈大佬之外,也有一些专业性的观点开始反驳Sora懂物理引擎这一说法。
比如下面这位推特博主,他认为OpenAI是数据驱动的物理引擎这一观点是荒谬愚蠢的,就好像收集了行星运动的数据并将它们喂给一个预测行星位置的模型,然后就得出该模型内部实现了广义相对论的结论。
他称,爱因斯坦花了很多年时间才推导出了重力理论的方程。如果有人认为随机梯度下降(SGD)+反向传播仅凭输入输出对就能理解一切,并在模型训练中解决问题,那这个人对于机器学习的理解是有问题的,对机器学习的工作方式了解也不够。
爱因斯坦在理论推导中对现实做出了很多假设,比如光速恒定、时空是灵活的结构,然后推导出了微分方程,其解揭示了黑洞、引力波等重大发现。可以说,爱因斯坦利用因果推理将不同的概念连接了起来。
但是,SGD+反向传播并不是这样,它们只是将信息压缩到模型权重中,并不进行推理,只是更新并转向实现具有最低误差的参数配置。
他认为,机器学习(ML)中的统计学习过程可能会显然低误差「盆地」,即无法探索不同的概念,因为一旦陷入这些低误差「盆地」或者局部最小值就无法重新开始。
因此,SGD+反向传播发现了看似有效但却很容易崩溃的、脆弱的解决方案捷径。这就是为什么深度学习系统不可靠并且实际训练起来很难,你必须在现实中不断更新和训练它们,这就很麻烦。
梯度下降的工作原理就像一只苍蝇寻找气味源一样,即苍蝇跟随空气中的化学浓度向下移动,从而引导它导向气味源。但如果仅依赖这种方式,则很容易迷路或陷入困境。
在机器学习中,模型的可调节参数就像苍蝇,训练数据就像气味源,目标函数测量的误差就像气味。而调整模型权重的目的是向着气味源(这里是低误差,相当于更浓的气味)移动。
最后,他得出结论,如果认为机器学习模型仅仅通过训练行星运动的视频就能在内部学到广义相对论,那就更荒谬了。这是对机器学习原理的严重误解。
此外,有网友指出Sora视频示例中充满了物理错误,比如一群小狗在雪中玩闹的场景就很糟糕,大块雪的运动就完全违反了重力(是否真如此,有待判断)。
Sora到底懂不懂物理?将来会不会懂?「预测下一个token」是不是通往AGI的一个方向?我们期待各路研究者进行进一步验证。
上一篇:小学老师群发寒假作业烂尾预警 还有同学没完成寒假作业吗
下一篇:最后一页





-
 Sora到底懂不懂物理世界?一场头脑风暴正在AI圈大佬间展开2024-02-20 09:34:26Sora到底是不是物理引擎甚至世界模型?图灵奖得主YannLeCun、Keras之父FrancoisChollet等人正在深入探讨。最近几天,OpenAI发布的视频生成模
Sora到底懂不懂物理世界?一场头脑风暴正在AI圈大佬间展开2024-02-20 09:34:26Sora到底是不是物理引擎甚至世界模型?图灵奖得主YannLeCun、Keras之父FrancoisChollet等人正在深入探讨。最近几天,OpenAI发布的视频生成模 -
 小学老师群发寒假作业烂尾预警 还有同学没完成寒假作业吗2024-02-20 09:31:542月18日,位于山东的学子们正迎来开学的倒计时,一场关于寒假奇迹的独特景象也在孩子们之间上演。伴随着泪水与不舍,他们开始了最后的冲刺
小学老师群发寒假作业烂尾预警 还有同学没完成寒假作业吗2024-02-20 09:31:542月18日,位于山东的学子们正迎来开学的倒计时,一场关于寒假奇迹的独特景象也在孩子们之间上演。伴随着泪水与不舍,他们开始了最后的冲刺 -
 上海飞大阪机票仅8元?平台回应2024-02-20 09:30:34话人间2月20日消息,海南万元机票难求之时,有网友惊奇的发现,从上海飞往日本大阪的机票,只要8到11元不等。据携程APP显示,8到11元的价格
上海飞大阪机票仅8元?平台回应2024-02-20 09:30:34话人间2月20日消息,海南万元机票难求之时,有网友惊奇的发现,从上海飞往日本大阪的机票,只要8到11元不等。据携程APP显示,8到11元的价格 -
 《甄嬛传》马拉松 24小时不间断播放2024-02-20 09:28:5719日台媒报道称,自2022年起台湾春节期间马拉松式24小时不间断播放《甄嬛传》,台媒直呼相当惊人!影视作品《甄嬛传》2011年在大陆播出时掀
《甄嬛传》马拉松 24小时不间断播放2024-02-20 09:28:5719日台媒报道称,自2022年起台湾春节期间马拉松式24小时不间断播放《甄嬛传》,台媒直呼相当惊人!影视作品《甄嬛传》2011年在大陆播出时掀 -
 杨迪爆改 网友:这个太吓人了2024-02-20 09:26:45杨迪也被爆改了!爆改后变成了浓眉大眼、五官立体的潮男帅哥,还戴了狼尾假发套。网友:杨迪老师换头术吗?还是原装的看着舒服,这个太吓人了
杨迪爆改 网友:这个太吓人了2024-02-20 09:26:45杨迪也被爆改了!爆改后变成了浓眉大眼、五官立体的潮男帅哥,还戴了狼尾假发套。网友:杨迪老师换头术吗?还是原装的看着舒服,这个太吓人了 -
 一箱八宝粥只有10罐其余都是泡沫 厂家:在箱子外包装上已经注明内含罐数2024-02-20 09:24:462月18日,一位安徽网友发视频称,家里的一箱八宝粥里只有10罐,包装箱其余部分都填充了泡沫,对此表示质疑。2月19日,厂家工作人员告诉话人
一箱八宝粥只有10罐其余都是泡沫 厂家:在箱子外包装上已经注明内含罐数2024-02-20 09:24:462月18日,一位安徽网友发视频称,家里的一箱八宝粥里只有10罐,包装箱其余部分都填充了泡沫,对此表示质疑。2月19日,厂家工作人员告诉话人 -
 东方甄选报警 回应南美白虾添加虾药2024-02-20 09:22:252月18日,知名打假人王海在社交平台账号上发布视频称,东方甄选自营厄瓜多尔南美白虾隐瞒添加并超量使用焦亚硫酸钠,涉嫌欺诈消费者。据中
东方甄选报警 回应南美白虾添加虾药2024-02-20 09:22:252月18日,知名打假人王海在社交平台账号上发布视频称,东方甄选自营厄瓜多尔南美白虾隐瞒添加并超量使用焦亚硫酸钠,涉嫌欺诈消费者。据中 -
 梅西13天3次回应均未道歉 希望再来中国2024-02-20 09:19:4719日,梅西发布视频否认中国香港行因政治等原因未出场并称与中国有着非常紧密和特别的缘分。据悉,梅西13天3次回应均未道歉。北京时间2月19
梅西13天3次回应均未道歉 希望再来中国2024-02-20 09:19:4719日,梅西发布视频否认中国香港行因政治等原因未出场并称与中国有着非常紧密和特别的缘分。据悉,梅西13天3次回应均未道歉。北京时间2月19 -
 返程路带上爱出发 年后告别的时刻总是有满满的不舍与牵挂2024-02-20 09:17:31年后告别的时刻总是有满满的不舍与牵挂,大家带上了爱与牵挂出发返程。冬去春来,岁月的车轮又滚过了一个轮回。在时光的深处,我仿佛听到了
返程路带上爱出发 年后告别的时刻总是有满满的不舍与牵挂2024-02-20 09:17:31年后告别的时刻总是有满满的不舍与牵挂,大家带上了爱与牵挂出发返程。冬去春来,岁月的车轮又滚过了一个轮回。在时光的深处,我仿佛听到了 -
 博主称已联系到“秦朗”母亲 律师:若摆拍或面临治安处罚2024-02-20 09:15:47近日,博主在巴黎厕所捡到小学生作业,引发网友热议。19日晚,博主再次回应:已联系上其妈妈。律师表示:若摆拍或面临治安处罚。2月16日下
博主称已联系到“秦朗”母亲 律师:若摆拍或面临治安处罚2024-02-20 09:15:47近日,博主在巴黎厕所捡到小学生作业,引发网友热议。19日晚,博主再次回应:已联系上其妈妈。律师表示:若摆拍或面临治安处罚。2月16日下